EngineeringAI TestingArchitecture
Planner, Generator, Evaluator: The Multi-Agent QA Architecture
Shiplight AI Team
Updated on June 30, 2026
Shiplight AI Team
Updated on June 30, 2026
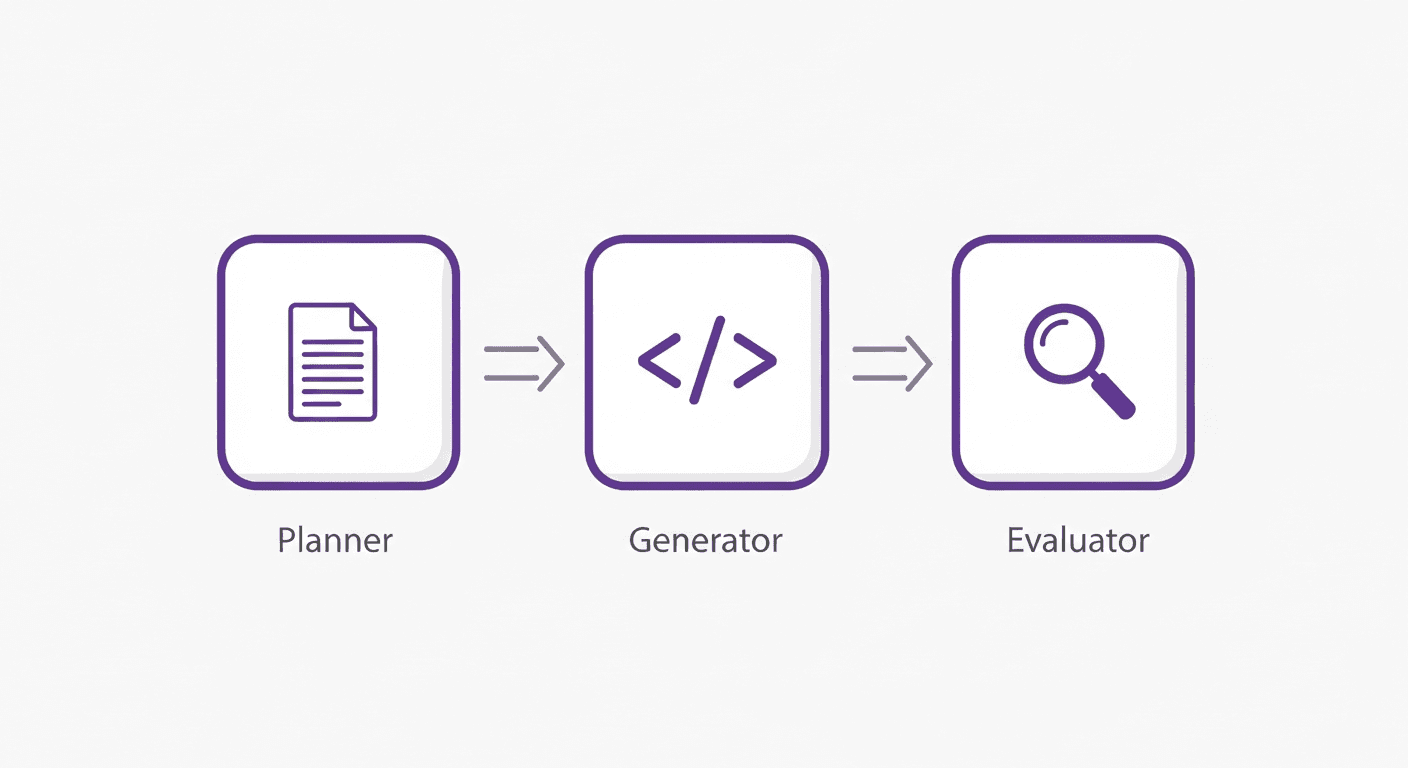
The Planner–Generator–Evaluator pattern is a multi-agent QA architecture where three specialized AI roles handle different parts of building and verifying software: the Planner decomposes a task, the Generator writes the code or test, and the Evaluator — structurally separate from both — judges whether the output is actually correct. OpenAI and Anthropic independently converged on this design because self-evaluation by the same agent that generated the output is unreliable.
---
Two AI research teams — OpenAI and Anthropic — independently published their internal architectures for building reliable software with AI coding agents. They used different terminology and arrived from different directions. But the structural conclusion was the same:
You need an independent evaluation layer that the generator cannot see past.
Anthropic called it the Evaluator. OpenAI built it as an agent-to-agent review loop with browser validation. Both found that without this layer, AI-generated software looks correct but isn't — and the generator has no reliable way to know the difference.
This post explains the architecture, why self-evaluation fails, and what the evaluator layer looks like in a production engineering workflow.
The intuitive solution to AI-generated code quality is to ask the AI to review its own work. It's cheaper than a human review cycle, and the model already understands what it wrote. This is wrong in a specific and important way.
Anthropic's research states it directly:
> "Tuning a standalone evaluator to be skeptical turns out to be far more tractable than making a generator critical of its own work. Models confidently praise mediocre work when grading their own output."
This isn't a model capability problem that better models will solve. It's a structural problem: the generator has an implicit prior toward its own output. It knows what it intended to build, and it interprets the output through that lens. A button that doesn't work looks like a button that works when you already know what the button is supposed to do.
The same dynamic appears in OpenAI's harness engineering work. Their response was to build explicit agent-to-agent review loops — separate agents that evaluate the generator's output — combined with browser validation that observes actual runtime behavior rather than code inspection.
Both teams converged on the same structural fix: separate the generator from the evaluator.
Anthropic's published architecture formalizes this into three roles:
Expands a brief prompt or user story into a detailed product specification. The Planner thinks about scope, edge cases, and acceptance criteria before any code is written. Its output is not code — it's a structured description of what correct behavior looks like.
Implements the specification. Takes the Planner's output and produces code, tests, CI configuration, and documentation. The Generator's job is throughput: generate correct output given a well-specified goal.
Tests the Generator's output against the Planner's specification. The critical design choice: the Evaluator must be tuned to be skeptical. It runs the application, checks behavior against acceptance criteria, and returns a structured assessment — not a rubber stamp.
In Anthropic's experiment, the same task run without an Evaluator (20 minutes, $9) produced broken core mechanics. With the full Planner → Generator → Evaluator loop (6 hours, $200), the output was functionally correct. The cost difference is real; so is the quality difference.
OpenAI's harness engineering team arrived at the same architecture through a different path. Rather than a formal Planner/Evaluator role structure, they built evaluation capability directly into the agent runtime:
> "We wired the Chrome DevTools Protocol into the agent runtime and created skills for working with DOM snapshots, screenshots, and navigation. This enabled Codex to reproduce bugs, validate fixes, and reason about UI behavior directly."
The result is functionally equivalent to an Evaluator: a layer that observes actual application behavior in a real browser and validates it against acceptance criteria — separate from the Generator's own assessment.
They describe the loop explicitly: for any given change, Codex validates the current state, implements a fix, drives the application to validate the fix, and loops until the behavior is correct. Only then does it open a pull request — with screenshot evidence attached.
This is the Planner/Generator/Evaluator architecture in practice, minus the formal labels.
Both implementations share one principle that teams often miss: the evaluation step must be structurally separated from the generation step.
This matters for three reasons:
What does this look like in practice for an engineering team?
The Planner's output — the specification — must be expressed in terms the Evaluator can check mechanically. "The checkout flow should work" is not evaluable. "After a user clicks Place Order, the order confirmation page should display an order number within 3 seconds" is.
Teams building this pattern typically encode acceptance criteria as:
AGENTS.md or a QUALITY_SCORE.md documentUI behavior cannot be validated by reading code. The evaluator must run the application and observe what actually happens — not what the code suggests should happen.
OpenAI's approach (Chrome DevTools Protocol, per-worktree app instances, DOM snapshots) is the right pattern. The implementation challenge is non-trivial: you need per-PR isolated environments, browser automation infrastructure, and an agent that can interpret screenshots and runtime behavior.
In an agent-first workflow, UI changes rapidly. Tests that are coupled to CSS selectors or DOM position break every time the generator refactors a component. The evaluator needs tests expressed as semantic intent — "click the primary checkout button" — that survive UI changes without manual updates.
This is the intent-cache-heal pattern: tests store intent, execution resolves against the live DOM. When the UI changes, the evaluator adapts rather than failing.
Building the Planner/Generator/Evaluator architecture from scratch requires significant infrastructure: browser automation, per-PR isolated environments, a test format that survives UI churn, and an agent runtime that can interpret visual output.
Shiplight Plugin provides this as a drop-in MCP tool for Claude Code, Cursor, and Codex. Your coding agent acts as the Generator. Shiplight provides the Evaluator:
When a test fails, the evidence goes back to the Generator — which implements a fix and requests another evaluation pass. This is the self-correcting loop that OpenAI describes running for up to six hours on complex tasks.
The tests themselves are written in Shiplight's YAML format:
goal: Verify checkout flow completes successfully
statements:
- intent: Add an item to the cart
- intent: Proceed to checkout
- intent: Enter valid payment information
- VERIFY: order confirmation page is displayed with an order numberWhen the Generator refactors the checkout component, the intent-based evaluator adapts. When a genuine regression breaks the flow, it catches it and reports back — before any human reviews the PR.
For teams with existing Playwright tests, Shiplight's AI SDK adds the evaluator layer without rewriting the suite.
The Planner/Generator/Evaluator pattern redefines what QA work means.
In a traditional workflow, QA executes: run test suites, file bugs, rerun after fixes. In an agent-first workflow with a proper evaluator layer, that execution is automated. The human QA role shifts to system design: writing acceptance criteria that the evaluator can check, calibrating the evaluator's skepticism level, and deciding what counts as a blocking failure vs. a follow-up issue.
This is higher-leverage work. One well-written acceptance criterion, encoded once, evaluates every PR that touches the relevant flow. One well-tuned evaluator gates thousands of agent-generated changes.
Teams that make this shift stop experiencing QA as a bottleneck. Teams that don't find themselves caught between agent throughput and manual verification capacity — which is exactly the wall OpenAI hit, and specifically why they had to build their own evaluator infrastructure.
A multi-agent system where three specialized roles handle different parts of software development: the Planner expands requirements into detailed specifications, the Generator implements those specifications as code, and the Evaluator tests the Generator's output against the Planner's requirements. The key insight is that evaluation must be structurally separated from generation — the same agent cannot reliably assess its own output.
Anthropic's research shows that models confidently rate their own output positively even when it's mediocre or broken. The generator has an implicit prior toward its own output — it interprets actual behavior through the lens of intended behavior. A standalone evaluator, tuned to be skeptical and run independently, catches failures the generator misses.
Traditional code review is a human reading code. The Planner/Generator/Evaluator pattern runs the application and checks actual behavior against specified requirements. This catches behavioral regressions that look correct in code review — especially UI behavior, timing issues, and cross-component interactions that only appear at runtime.
No. The evaluator layer is useful regardless of how code is generated. If you use AI coding agents (Claude Code, Cursor, Codex), the evaluator closes the feedback loop automatically. If humans write the code, the evaluator still provides behavioral verification faster than a manual QA cycle.
Start with Shiplight Plugin as the evaluator component in your CI pipeline. Define acceptance criteria for your critical user flows as intent-based YAML tests. Wire Shiplight into your GitHub Actions workflow to run the evaluator on every PR. See E2E testing in GitHub Actions for the workflow setup and testing layer for AI coding agents for the broader architectural context.
---
Related: the human QA bottleneck in agent-first teams · what is self-healing test automation · QA for the AI coding era · intent-cache-heal pattern
Add the evaluator layer your agents are missing. Try Shiplight Plugin — free, no account required · Book a demo
References: OpenAI Harness Engineering, Anthropic Harness Design for Long-Running Apps, Playwright documentation