AI TestingGuidesBest Practices
What Is Software Testing? Definitions, Types, Levels, and Methods (2026 Guide)
Shiplight AI Team
Updated on June 26, 2026
Shiplight AI Team
Updated on June 26, 2026
Software testing is the systematic practice of verifying that a software product behaves the way it is supposed to — and finding the places where it doesn't, before users do. The discipline is built around four test levels (unit, integration, system, acceptance), a dozen named test types (functional, regression, performance, security, exploratory, and more), two authorship models (manual and automated), and seven foundational principles ratified by the ISTQB. This guide walks through every fundamental, with clear definitions, examples, and the modern context: how AI coding agents and intent-based testing are changing the practice without changing the basics. For the "what's new in 2026" angle, pair this guide with software testing basics in 2026.
Software testing is the process of evaluating a software product to determine whether it meets specified requirements and identifies defects. It has two complementary purposes:
Both perspectives matter and a complete testing strategy covers both. A product that passes every unit test can still be the wrong product. A product that everyone says solves their problem can still have memory leaks that crash it under load. Software testing answers both questions, at different levels of abstraction.
For the broader category that adds artificial intelligence into the testing function, see what is AI testing. For the specifically 2026 framing of what the basics look like today, see software testing basics in 2026.
Three categories of value:
The clearest argument for software testing basics is the record of what untested or under-tested software has cost — and the failure mode has shifted toward AI-introduced defects in the 2020s:
Recent large-scale software failures
AI-specific failures (the 2020s failure mode)
Classic textbook cases (still worth knowing)
The pattern is consistent across four decades: each failure was a defect a disciplined testing process was designed to catch. What changed in the 2020s is where the defects come from — increasingly from AI-generated code and AI features that are plausible but wrong, shipped without an output-validation layer (see testing strategy for AI-generated code and how to test vibe-coded applications for reliability). The case for software testing has not weakened in 30 years; the cost structure flipped — testing used to be the slow thing that compressed against deadlines; in 2026, well-designed automated testing is faster than the development cycle it gates.
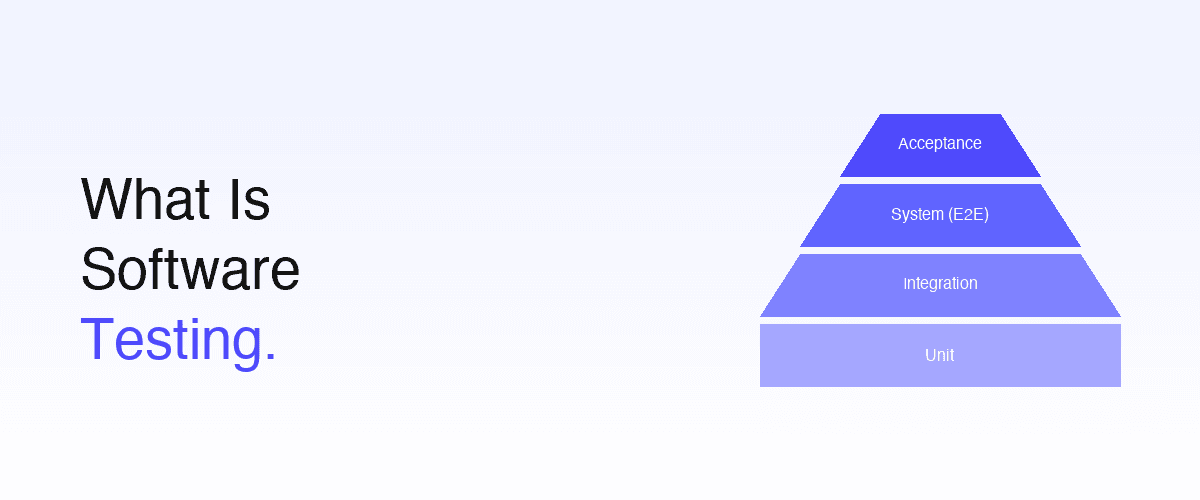
Software testing is organized by level of integration — from a single function up to the full deployed product. The "test pyramid" visualization captures the canonical distribution:
| Level | Tests What | Speed | Volume | Typical Tools |
|---|---|---|---|---|
| Unit | Single function, class, or module in isolation | Milliseconds | High (1,000s) | Jest, JUnit, pytest, RSpec |
| Integration | Two or more modules / services working together | Seconds | Medium (100s) | Supertest, Pact, language-specific frameworks |
| System (end-to-end) | The whole application as a user experiences it | Tens of seconds | Lower (10s–100s) | Playwright, Cypress, Selenium, Shiplight |
| Acceptance | The product against user / business criteria | Variable | Lowest (handful) | Manual sign-off; cucumber-style BDD; UAT |
The pyramid shape reflects an economic reality: unit tests are cheap and fast, so you can have many; system and acceptance tests are slower and more expensive to maintain, so you have fewer of them but they catch a different (and more user-visible) class of defect.
Tests a single unit of code (function, method, class) in isolation, with dependencies mocked or stubbed. A unit test confirms the unit's behavior — given these inputs, the unit returns these outputs or raises this error. Unit tests run in milliseconds and are typically written by the engineer who wrote the code, often alongside it (test-driven development).
Tests that two or more modules work together correctly across their interfaces. Integration tests run slower than unit tests because they involve real (or near-real) collaborators — actual database connections, real HTTP calls between services, genuine queue producers and consumers. They catch the bugs that live between units, which unit tests by design cannot.
See E2E testing vs integration testing for the boundary between this level and the next.
Tests the entire application as deployed, from the user's entry point through the full system. A system test of an e-commerce checkout exercises the frontend, the order service, the inventory service, the payment gateway, and the email service — every layer the user's action touches. This level is where the 2026 evolution is most visible: intent-based authoring and self-healing are replacing selector-bound Playwright as the dominant model. See the E2E coverage ladder and near-zero maintenance E2E testing.
Tests the product against acceptance criteria — defined by the user, the customer, or the business. Acceptance testing answers the validation question: is this the right product? Often manual, sometimes automated as part of BDD frameworks. User Acceptance Testing (UAT) is the canonical sub-category, where the actual user (not a developer) confirms the product meets their needs.
Test levels cut by integration depth. Test types cut by what is being verified. The major types every team should know:
Verifies that each feature does what its specification says it should do. The largest category by volume. Includes the bulk of unit, integration, and system tests.
Verifies how well the system performs, not just whether it works. Sub-categories:
Re-runs previously-passing tests after a change to confirm the change didn't break existing behavior. The single largest category by count in any mature test suite — every test you've ever written becomes part of the regression set. See from natural language to release gates.
A small, fast subset of tests that runs on every build or deploy to verify the system is not obviously broken. If the smoke test fails, you don't bother running the full regression — you have a more fundamental problem.
A narrow, targeted retest of the specific area changed in a release, to confirm a specific bug fix or new feature works as expected. Smaller than a smoke test, more focused.
A human tester actively explores the application without a pre-written script, looking for surprising failures. The bug class exploratory testing catches — surprising user paths, unexpected combinations, "I didn't expect that" issues — is the bug class automation is worst at finding. In the AI era, exploratory testing is more important, not less, because AI handles the regression floor and frees QA engineers to spend more time exploring. See the QA role in the AI era.
Compares screenshots of UI components or pages across versions to detect unintended visual changes — a layout shift, a color regression, a missing icon. Often AI-augmented with visual diff scoring to reduce false positives from anti-aliasing or rendering jitter.
Distinct from levels and types, methods describe how the test is executed:
Most teams need both. Manual testing for exploratory work and new-feature validation; automated for regression and CI gates. See test authoring methods compared for the deeper breakdown.
Unit tests are typically white-box (you can see the function you're testing). System tests are typically black-box (you exercise the UI without caring how the backend implements it).
Both are part of a complete testing strategy. A 2026 team uses static analysis on every save (TypeScript, ESLint, code review with AI assistance) and dynamic tests at unit, integration, and system levels on every PR.
The standard sequence of activities that produces software testing work:
The STLC is iterative — in continuous deployment environments, it runs on every PR rather than once per release. See the modern E2E workflow for the agile-style cycle.
The International Software Testing Qualifications Board codified seven principles that still hold in 2026:
These principles predate AI agents, predate cloud computing, predate microservices — they still apply.
Every software testing basics reference uses the same core vocabulary. The terms you will see most often:
For the full, continuously-updated vocabulary of modern QA, see the AI testing glossary.
The fundamentals above (levels, types, methods, principles) are stable. What is changing rapidly is the execution layer — specifically how tests are authored, maintained, executed, and analyzed. Five 2026 shifts to know:
For the full 2026 modernization story, see software testing basics in 2026 and AI in test automation.
The honest landscape across categories:
| Category | Representative tools | Where they fit |
|---|---|---|
| Unit testing frameworks | Jest, Vitest, JUnit, pytest, RSpec, Go test | Unit level, language-native |
| Integration testing | Supertest, Postman, Pact, REST Assured | API contracts and service boundaries |
| Code-bound E2E | Playwright, Cypress, Selenium, WebdriverIO | System level, traditional automation |
| Intent-based E2E | Shiplight YAML, testRigor | System level, natural-language authoring |
| AI-augmented E2E platforms | Mabl, Testim, Katalon AI | System level, AI features on script-based core |
| Agentic QA platforms | Shiplight Plugin, QA Wolf | System level + agent integration |
| Visual testing | Applitools, Percy, Chromatic | Visual regression sub-category |
| Performance testing | k6, JMeter, Gatling, Locust | Non-functional load and latency |
| Security testing | OWASP ZAP, Burp Suite, Snyk, Dependabot | Non-functional vulnerability scanning |
For deeper comparisons, see best AI testing tools in 2026, best AI automation tools for software testing, and best agentic QA tools in 2026.
Software testing is the practice of running a software product through a planned set of scenarios to verify it behaves the way it is supposed to, and to find the places where it doesn't. The practice has two purposes: verification (are we building the product correctly?) and validation (are we building the right product for the user?). Testing happens at multiple levels of integration — unit, integration, system, and acceptance — and uses both manual human-execution and automated machine-execution.
The major categories: functional testing (does the feature do what its spec says?), regression testing (did this change break previously-working behavior?), smoke testing (is the build at all working?), performance testing (is it fast and scalable?), security testing (is it safe from vulnerabilities?), usability testing (can users actually use it?), accessibility testing (does it work for users with disabilities?), exploratory testing (what surprises us when a human pokes at it?), and visual regression testing (does it look the way it should?).
The four canonical levels, in increasing scope: (1) unit testing — single functions or classes in isolation; (2) integration testing — multiple modules or services working together; (3) system testing (also called end-to-end or E2E) — the whole application as a user experiences it; (4) acceptance testing — the product against user or business acceptance criteria. The "test pyramid" visualization captures the recommended distribution: many unit tests, fewer integration, fewer still system, smallest at acceptance.
Manual testing is human-executed — a person follows test steps and observes outcomes. Best for exploratory testing, UAT, accessibility, and any verification that requires human judgment. Automated testing is machine-executed — a script or AI system runs the steps and records outcomes. Best for regression, repeatable scenarios, and CI/CD gates. Most teams need both; they are complementary, not substitutes.
Verification asks "are we building the product correctly?" — does the implementation match the specification? Did the code do what it was designed to do? Verification is typically the focus of unit, integration, and system testing. Validation asks "are we building the right product?" — does it solve the user's actual problem? Will users adopt it? Validation is typically the focus of acceptance testing, UAT, and exploratory work.
The test pyramid is a visualization that shows the recommended distribution of test types across the four levels. The pyramid is widest at the bottom (many fast, cheap unit tests), narrower in the middle (fewer integration tests), and narrowest at the top (handful of system / E2E tests). The shape reflects an economic reality: unit tests are cheap and fast, system tests are slower and more expensive to maintain — so you have many of the former and fewer of the latter. The 2026 evolution: intent-based authoring + self-healing has dropped the maintenance cost of system tests, allowing teams to have more system-level coverage than the classic pyramid suggested.
Not exactly. Software testing is a specific practice — designing, executing, and analyzing tests to find defects and verify behavior. Quality assurance (QA) is the broader discipline that includes testing plus process design, quality policy, code review practices, defect-prevention strategy, and the human roles that own all of the above. Testing is something you do; QA is a function that owns testing plus more. See the QA role in the AI era.
The ISTQB seven principles: (1) testing shows the presence of defects, not absence; (2) exhaustive testing is impossible; (3) early testing saves time and money; (4) defects cluster; (5) the pesticide paradox — repeated tests stop finding new bugs; (6) testing is context-dependent; (7) the absence-of-errors fallacy — software with no defects is still useless if it doesn't solve the user's problem.
AI changes the execution layer, not the fundamentals. The four big shifts: (1) intent-based authoring replaces selector-bound automation — tests are written in natural language and resolved to the DOM at runtime; (2) self-healing as default — tests survive UI refactors without manual intervention; (3) agent-native verification — AI coding agents author tests via SDK / MCP integration in the same session they write features; (4) PR-time CI gates replace nightly regression as the primary quality gate. The four test levels, the major test types, and the seven principles all still apply. See software testing basics in 2026.
Three concrete steps: (1) read this guide plus software testing basics in 2026 to understand the fundamentals plus the modern context; (2) pick a small project and write unit tests for one module — using Jest if you're in JavaScript, pytest for Python, JUnit for Java; (3) when comfortable with unit, add one E2E test for the most critical user flow using an intent-based tool like Shiplight YAML. The pattern: start narrow, expand vertically (more depth in one area) before going horizontal (multiple areas).
---
Software testing as a discipline rests on a stable foundation — four test levels, a dozen test types, two authorship methods, seven principles. None of that has changed since the 1990s, and none of it is going to change in 2026, 2027, or the years after. What is changing rapidly is the practice — how tests are authored (intent-based, not selector-bound), maintained (self-healing, not manual repair), executed (PR-time, not nightly), and analyzed (AI-clustered failures, not engineer-by-engineer triage).
For teams ready to apply the fundamentals with the 2026 modern practice, Shiplight AI is a system that combines all the layers: YAML Test Format for intent-based system-level tests, AI SDK and MCP Server for agent-native authoring, AI Fixer for self-healing on every run, and Cloud runners for PR-time gates. Book a 30-minute walkthrough and we'll map your current testing practice to each fundamental and project the modernization delta.